wir haben in einem Fujitsu-Bladecenter 10 Blades für ein Terminal-basierendes Browser-System (Recobs) in Betrieb.
Über einen FreeNX-Server werden Firefox-Sessions an die User ausgeliefert.
Die Server werden über einen Loadbalancer im Round-Robin-Betrieb zugeteilt.
Bisher war es so, dass jeder User auf jedem Server ein Home-Verzeichnis und ein Firefox-Profil hatte.
Landete er bei der nächsten Anmeldung auf einem anderen Server wurden die relevanten Daten des Firefox-Profils
(Lesezeichen, Chronik) auf den aktuellen Server kopiert und dann die Session gestartet.
Etwas umständlich, hat aber 10 Jahre lang (mehr oder weniger) gut funktioniert.
Da nun ein aktuellerer Browser notwendig wurde (TLS 1.2 usw.) haben wir auch neue Hardware beschafft.
Die 10 neuen Blades haben je 2 Xeon E5-2640 @ 2.40GHz und je 256 GB RAM.
Um die Home-Verzeichnisse und damit auch die Firefox-Daten zu zentralisieren haben wir glusterFS installiert.
Ein Volume wird auf allen Servern nach /home gemounted.
Auf den Servern ist Debian 8.9 installiert.
Als Firefox kommt der 45.8 ESR zum Einsatz.
Diese Installation haben wir vorher, noch auf der alten Hardware mit 4 Servern mehrere Monate lang getestet.
Das Volume bestand hier aus 4 Bricks und war distributed-replicated (replica 2).
Allerdings standen uns "nur" 350 Tester zur Verfügung, von denen ca 50 gleichzeitig online waren, also ca. 12 - 13 pro Server.
In dem neuen System mit den 10 neuen Blades liegt /home auf einem distributed-replicated (replica 3) Volume mit 9 Bricks.
Inzwischen existieren dort über 5000 Home-Verzeichnissse und pro Server sind in Spitzenzeiten 100 - 120 User online.
Nach ca. einer Woche begannen die Probleme.
Authentifizierungen über ssh und /oder winbind waren plötzlich sporadisch nicht mehr möglich und Prozesse liessen sich nicht mehr starten.
Die Fehlermeldung lautet immer bash: fork: Nicht genügend Hauptspeicher verfügbar
Hier ein Anmeldeversuch mit putty und Ausgabe von free -h:
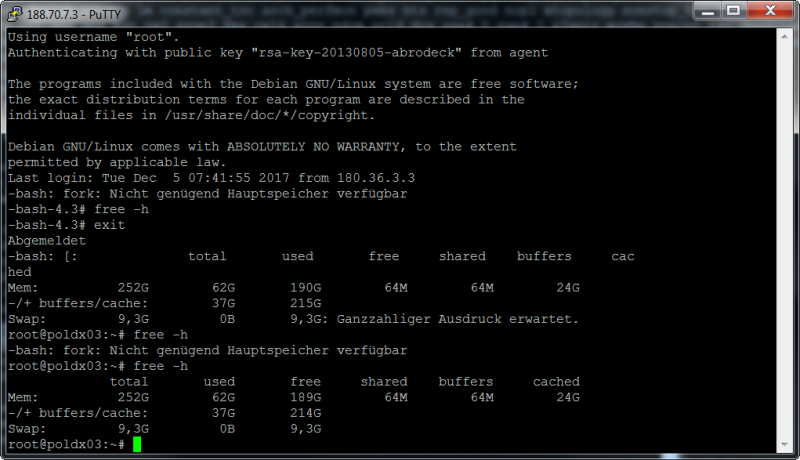
Zu der Zeit waren auf diesem Server 93 User online.
Laut Google sind solche Probleme mit Anpassungen von Kernel-Parametern zu beheben.
Folgende Parameter haben wir bisher augepasst (/etc/sysctl.d/gluster_opt.conf):
in Klammern stehen die default-Werte
------------------------------------------------------------------------------------------------------------------
# Shared Memory Limits
######################
kernel.shmmni = 65536 (4096)
# Messages Limits
#################
kernel.msgmax = 65536 (8192)
kernel.msgmnb = 65536 (16384)
kernel.msgmni = 262144 (32768)
# Semaphore Limits
##################
#kernel.sem = <SEMMSL> <SEMMNS> <SEMOPM> <SEMMNI>
kernel.sem = 250 1024000 32 65536 (250 32000 32 128)
# Netzwerk
##########
net.core.rmem_default = 212992
net.core.rmem_max = 4259840 (212992)
net.core.wmem_default = 212992
net.core.wmem_max = 1064960 (212992)
net.ipv4.tcp_keepalive_time = 300 (7200)
# Dateizugriff
##############
fs.aio-max-nr = 1064960 (65536)
fs.file-max = 26450162 (26450163)
fs.mqueue.msg_max = 8192 (10)
#VM
###
vm.swappiness = 1 (60)
vm.vfs_cache_pressure = 300 (100)
vm.dirty_background_ratio = 5 (10)
vm.dirty_ratio = 10 (20)
vm.admin_reserve_kbytes=32768 (8192)
Leider haben die Änderungen wenn überhaupt, dann nur kurzzeitig Verbesserungen gezeigt.
Weiterhin sind zu manchen Parametern differierende Aussagen zu finden.
Wir suchen also nach wie vor die Ursache für diese Fehlermeldung und
die entsprechenden Parameter mit denen sie beseitigt werden kann.
Ich hoffe, ich habe unser Problem verständlich dargelegt und bin für jede erdenkliche Hilfe dankbar!
Gruß
Andreas


